 USEMO Problem Development, Behind the Scenes
USEMO Problem Development, Behind the Scenes
In this post I’m hoping to say a bit about the process that’s used for the problem selection of the recent USEMO: how one goes from a pool of problem proposals to a six-problem test. (How to write problems is an entirely different story, and deserves its own post.) I choose USEMO for concreteness here, but I imagine a similar procedure could be used for many other contests.
I hope this might be of interest to students preparing for contests to see a bit of the behind-the-scenes, and maybe helpful for other organizers of olympiads.
The overview of the entire timeline is:
- Submission period for authors (5-10 weeks)
- Creating the packet
- Reviewing period where volunteers try out the proposed problems (6-12 weeks)
- Editing and deciding on a draft of the test
- Test-solving of the draft of the test (3-5 weeks)
- Finalizing and wrap-up
Now I’ll talk about these in more detail.
Pinging for problems
The USA has the rare privilege of having an extremely dedicated and enthusiastic base of volunteers, who is going to make the contest happen rain or shine. When I send out an email asking for problem proposals, I never really worry I won’t get enough people. You might have to adjust the recipe below if you have fewer hands on deck.
When you’re deciding who to invite, you have to think about a trade-off between problem security versus openness. The USEMO is not a high-stakes competition, so it accepts problems from basically anyone. On the other hand, if you are setting problems for your country’s IMO team selection test, you probably don’t want to take problems from the general public.
Submission of the problem is pretty straightforward, ask to have problems emailed as TeX, with a full solution. You should also ask for any information you care about to be included: the list of authors of the problem, any other collaborators who have seen or tried the problem, and a very rough estimate of how hard the difficulty is. (You shouldn’t trust the estimate too much, but I’ll explain in a moment why this is helpful.)
Ideally I try to allocate 5-10 weeks between when I open submissions for problems and when the submission period ends.
It’s at this time you might as well see who is going to be interested in being a test-solver or reviewer as well — more on that later.
Creating the packet
Once the submission period ends, you want to then collate the problems into a packet that you can send to your reviewers. The reviewers will then rate the problems on difficulty and suitability.
A couple of minor tips for setting the packet:
- I used to try to sort the packet roughly by difficulty, but in recent years I’ve switched to random order and never looked back. It just biases the reviewers too much to have the problem number matter. The data has been a lot better with random order.
- Usually I’ll label the problems A-01, A-02, … A-05 (say), C-06, C-07, … and so on. The leading zero is deliberate: I’ve done so much IMO shortlist that if I see a problem named “C7”, it will automatically feel like it should be a hard problem, so using “C-07” makes this gut reaction go away for me.
- It’s debatable whether you need to have subject classifications at all, since in some cases a problem might not fit cleanly, or the “true” classification might even give away the problem. I keep it around just because it’s convenient from an administrative standpoint to have vaguely similar problems grouped together and labelled, but I’ll explicitly tell reviewers to not take the classification seriously, rather as a convenience.
More substantial is the choice of which problems to include in the packet if you are so lucky to have a surplus of submissions. The problem is that reviewers only have so much time and energy and won’t give as good feedback if the packet is too long. In my experience, 20 problems is a nice target, 30 problems is strenuous, anything more than that is usually too much. So if you have more than 30 problems, you might need to cut some problems out.
Since this “early cutting” is necessarily pretty random (because you won’t be able to do all the problems yourself singe-handedly) , I usually prefer to do it in a slightly more egalitarian way. For example, if one person submits a lot of problems, you might only take a few problems from them, and say “we had a lot of problems, so we took the 3 of yours we liked the most for review”. (That said, you might have a sense that certain problems are really unlikely to be selected, and so you might as well exclude those.)
You usually also want to make sure that you have a spread of difficulties and subjects. Actually, this is even more true if you don’t have a surplus: if it turns out that, say, you have zero easy algebra or geometry problems, that’s likely to cause problems for you later down the line. It might be good to see if you can get one or two of those if you can. This is why the author’s crude estimates of difficulty can still be useful — it’s not supposed to be used for deciding the test, but it can give you “early warnings” that the packet might be lacking in some area.
One other useful thing to do, if you have the time at this point, is to edit the proposals as they come in, before adding them onto the packet. This includes both making copy edits for clarity and formatting, as well as more substantial changes if you can see an alternate version or formulation that you think is likely to be better than the original. The reason you want to do this step now is that you want the reviewer’s eyes on these changes: making edits halfway through the review process or after it can cause confusion and desynchronization in the reviewer data, and increases the chances of errors (because the modifications have been checked fewer times).
The packet review process
Then comes the period where your reviewers will work through the problems and submit their ratings. This is also something where you want to give reviewers a lot of time: 6-8 weeks is a comfortable amount. Between 10 and 25 reviewers is a comfortable number.
Reviewers are asked to submit a difficulty rating and quality rating for each problem. The system I’ve been using, which seems to work pretty well, goes like follows:
- The five possible quality ratings are “Unsuitable”, “Mediocre”, “Acceptable”, “Nice”, “Excellent”. I’ve found that this choice of five words has the connotations needed to get similar distributions of calibrations across the reviewers.
- For difficulty, I like to provide three checkboxes “IMO1”, “IMO2”, “IMO3”, but also tell the reviewer that they can check two boxes if, say, they think a problem could appear as either IMO1 or IMO2. That means in essence five ratings {1, 1.5, 2, 2.5, 3} are possible.
This is what I converged on as far as scales that are granular enough to get reasonable numerical data without being so granular that they are unintuitive or confusing. (If your scale is too granular, then a person’s ratings might say more about how a person interpreted the scale than the actual content of the problem.) For my group, five buckets seems to be the magic number; your mileage may vary!
More important is to have lots of free text boxes so that reviewers can provide more detailed comments, alternate solutions, and so on. Those are ultimately more valuable than just a bunch of numbers.
Here’s a few more tips:
- If you are not too concerned about security, it’s also nice to get discussion between reviewers going. It’s more fun for the reviewers and the value of having reviewers talk with each other a bit tends to outweigh the risk of bias.
- It’s usually advised to send only the problem statements first, and then only send the solutions out about halfway through. I’ve found most reviewers (myself included) appreciate the decreased temptation to look at solutions too early on.
- One thing I often do is to have a point person for each problem, to make sure every problem is carefully attempted This is nice, but not mandatory — the nicest problems tend to get quite a bit of attention anyways.
- One thing I’ve had success with is adding a question on the review form that asks “what six problems would you choose if you were making the call, and why?” I’ve found I get a lot of useful perspective from hearing what people say about this.
I just use Google Forms to collect all the data. There’s a feature you can enable that requires a sign-in, so that the reviewer’s responses are saved between sessions and loaded automatically (making it possible to submit the form in multiple sittings).
Choosing the draft of the test
Now that you have the feedback, you should pick a draft of the test! This is the most delicate part, and it’s where it is nice to have a co-director or small committee if possible so that you can talk out loud and bounce ideas of each other.
For this stage I like to have a table with the numerical ratings as a summary of what’s available. The way you want to do this is up to you, but some bits from my workflow:
- My table is color-coded, and it’s sorted in five different ways: by problem number, by quality rating, by difficulty rating, by subject then quality rating, by subject then difficulty rating.
- For the quality rating, I use the weights -0.75, -0.5, 0, 1, 1.5 for Unsuitable, Mediocre, Acceptable, Nice, Excellent. This fairly contrived set of weights was chosen based on some experience in which I wanted to the average ratings to satisfy a couple properties: I wanted the sign of the rating (- or +) to match my gut feeling, and I wanted to not the rating too sensitive to a few Unsuitable / Excellent ratings (either extreme). This weighting puts a “cliff” between Acceptable and Nice, which empirically seems a good place to make the most differential.
- I like to include a short “name” in the table to help with remembering which problem numbers are which, e.g. “2017-vtx graph”.
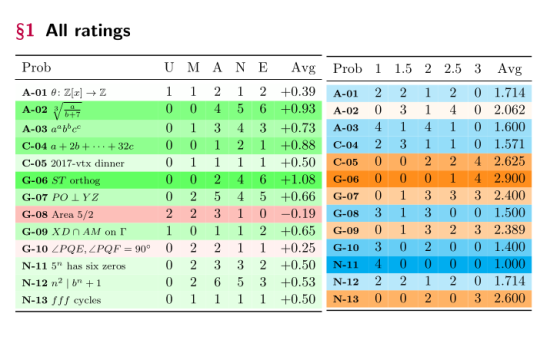
Here is a output made with fake data. Here’s the source code for the Python generator for anyone that wants to use it.
Of course, obligatory warning to not overly rely on the numerical ratings and to put heavy weight on the text comments provided. (The numerical ratings will often have a lot of variance, anyways.)
One thing to keep in mind is that when choosing the problems is that there are two most obvious goals are basically orthogonal. One goal is to have the most attractive problems (“art”), but the other is to have an exam which is balanced across difficulty and subject composition (“science”). These two goals will often compete with each other and you’ll have to make judgment calls to prioritize one over the other.
A final piece of advice is to not be too pedantic. For example, I personally dislike the so-called “Geoff rule” that 1/2/4/5 should be distinct subjects: I find that it is often too restrictive in practice. I also support using “fractional distributions” in which say a problem can be 75% number theory and 25% combinatorics (rather than all-or-nothing) when trying to determine how to balance the exam. This leads to better, more nuanced judgments than insisting on four categories.
This is also the time to make any last edits you want to the problems, again both copy edits or more substantial edits. This gives you a penultimate draft of the exam.
Test solving
If you can, a good last quality check to do is to have a round of test-solving from an unbiased group of additional volunteers who haven’t already seen the packet. (For the volunteers, this is a smaller time commitment than reviewing an entire packet so it’s often feasible as an intermediate commitment.) You ask this last round of volunteers to try out the problems under exam-like conditions, although I find it’s not super necessary to do a full 4.5 hours or have full write-ups, if you’ll get more volunteers this way. A nice number of test-solvers is 5-10 people.
Typically this test-solving is most useful as a sanity check (e.g. to make sure the test is not obviously too difficult) and for any last minute shuffling of the problems (which often happens). I don’t advise making drastic changes at this point. It’s good as a way to get feedback on the most tricky decisions, though.
Wrap-up
After any final edits, I recommend sending a copy of the edited problems and solutions to the reviewers and test-solvers. They’re probably interested to know what problems made the cut, and you want to have eyes going through the final paper to check for ambiguities or errors.
I usually take the time to also send out some details of the selection itself: what the ratings for the problems looked like, often a sentence or two for each problem about the overall feedback, and a documentation of my thought process in the draft selection. It’s good to give people feedback on their problems, in my experience the authors usually appreciate it a lot, especially if they decide to re-submit the problem elsewhere.
And that’s the process.