 A story of block-ascending permutations
A story of block-ascending permutations
I recently had a combinatorics paper appear in the EJC. In this post I want to brag a bit by telling the “story” of this paper: what motivated it, how I found the conjecture that I originally did, and the process that eventually led me to the proof, and so on.
This work was part of the Duluth REU 2017, and I thank Joe Gallian for suggesting the problem.
1. Background
Let me begin by formulating the problem as it was given to me. First, here is the definition and notation for a “block-ascending” permutation.
Definition 1. For nonnegative integers , …, an -ascending permutation is a permutation on whose descent set is contained in .
In other words the permutation ascends in blocks of length , , …, , and thus has the form for which for all .
It turns out that block-ascending permutations which also avoid an increasing subsequence of certain length have nice enumerative properties. To this end, we define the following notation.
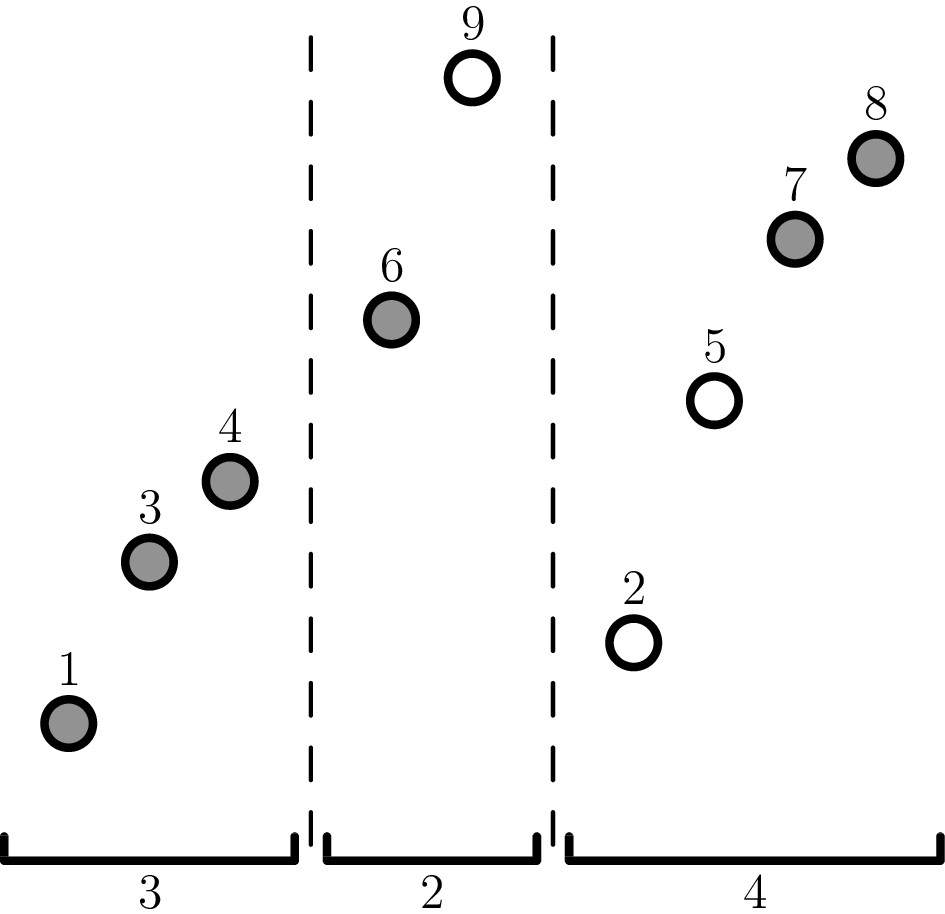
Definition 2. Let denote the set of -ascending permutations which avoid the pattern .
(The reason for using will be explained later.) In particular, if .
Example 3. Here is a picture of a permutation in (but not in , since one can see an increasing length subsequence shaded). We would denote it .
Now on to the results. A 2011 paper by Joel Brewster Lewis (JBL) proved (among other things) the following result:
Theorem 4 (Lewis 2011)
The sets and \mathcal L_{k+2}(k+1,k+1,\dots,k+1} are in bijection with Young tableau of shape .
Remark 5. When , this implies , which is the set of -avoiding permutations of length , is in bijection with the Catalan numbers; so is which is the set of -avoiding zig-zag permutations.
Just before the Duluth REU in 2017, Mei and Wang proved that in fact, in Lewis’ result one may freely mix and ’s. To simplify notation,
Definition 6. Let . Then denotes where
Theorem 7 (Mei, Wang 2017)
The sets are also in bijection with Young tableau of shape .
The proof uses the RSK correspondence, but the authors posed at the end of the paper the following open problem:
Problem
Find a direct bijection between the sets above, not involving the RSK correspondence.
This was the first problem that I was asked to work on. (I remember I received the problem on Sunday morning; this actually matters a bit for the narrative later.)
At this point I should pause to mention that this notation is my own invention, and did not exist when I originally started working on the problem. Indeed, all the results are restricted to the case where for each , and so it was unnecessary to think about other possibilities for : Mei and Wang’s paper use the notation . So while I’ll continue to use the notation in the blog post for readability, it will make some of the steps more obvious than they actually were.
2. Setting out
Mei and Wang’s paper originally suggested that rather than finding a bijection for any and , it would suffice to biject and then compose two such bijections. I didn’t see why this should be much easier, but it didn’t seem to hurt either.
As an example, they show how to do this bijection with and . Indeed, suppose . Then is an increasing sequence of length right at the start of . So had better be the largest element in the permutation: otherwise later in the biggest element would complete an ascending permutation of length already! So removing gives a bijection between .
But if you look carefully, this proof does essentially nothing with the later blocks. The exact same proof gives:
Proposition 8. Suppose . Then there is a bijection by deleting the -st element of the permutation (which must be largest one).
Once I found this proposition I rejected the initial suggestion of specializing . The “easy case” I had found told me that I could take a set and delete the single element from it. So empirically, my intuition from this toy example told me that it would be easier to find bijections whee and were only “a little different”, and hope that the resulting bijection only changed things a little bit (in the same way that in the toy example, all the bijection did was delete one element). So I shifted to trying to find small changes of this form.
3. The fork in the road
3.1. Wishful thinking
I had a lucky break of wishful thinking here. In the notation with , I had found that one could replace with either or freely. (But this proof relied heavily on the fact the block really being on the far left.) So what other changes might I be able to make?
There were two immediate possibilities that came to my mind.
- Deletion: We already showed could be changed from to for any . If we can do a similar deletion with for any , not just , then we would be done.
- Swapping: If we can show that two adjacent ’s could be swapped, that would be sufficient as well. (It’s also possible to swap non-adjacent ’s, but that would cause more disruption for no extra benefit.)
Now, I had two paths that both seemed plausible to chase after. How was I supposed to know which one to pick? (Of course, it’s possible neither work, but you have to start somewhere.)
Well, maybe the correct thing to do would have to just try both. But it was Sunday afternoon by the time I got to this point. Granted, it was summer already, but I knew that come Monday I would have doctor appointments and other trivial errands to distract me, so I decided I should pick one of them and throw the rest of the day into it. But that meant I had to pick one.
(I confess that I actually already had a prior guess: the deletion approach seemed less likely to work than the swapping approach. In the deletion approach, if is somewhere in the middle of the permutation, it seemed like deleting an element could cause a lot of disruption. But the swapping approach preserved the total number of elements involved, and so seemed more likely that I could preserve structure. But really I was just grasping at straws.)
3.2. Enter C++
Yeah, I cheated. Sorry.
Those of you that know anything about my style of math know that I am an algebraist by nature — sort of. It’s more accurate to say that I depend on having concrete examples to function. True, I can’t do complexity theory for my life, but I also haven’t been able to get the hang of algebraic geometry, despite having tried to learn it three or four times by now. But enumerative combinatorics? OH LOOK EXAMPLES.
Here’s the plan: let . Then using a C++ computer program:
- Enumerate all the permutations in .
- Enumerate all the permutations in .
- Enumerate all the permutations in .
If the deletion approach is right, then I would hope and look pretty similar. On the flip side, if the swapping approach is right, then and should look close to each other instead.
It’s moments like this where my style of math really shines. I don’t have to make decisions like the above off gut-feeling: do the “data science” instead.
3.3. A twist of fate
Except this isn’t actually what I did, since there was one problem. Computing the longest increasing subsequence of a length permutation takes time, and there are or so permutations. But when , we have , which is a pretty big number. Unfortunately, my computer is not really that fast, and I didn’t really have the patience to implement the “correct” algorithms to bring the runtime down.
The solution? Use instead.
In a deep irony that I didn’t realize at the time, it was this moment when I introduced the notation, and for the first time allowed the to not be in . My reasoning was that since I was only doing this for heuristic reasons, I could instead work with and probably not change much about the structure of the problem, while replacing , which would run times faster. This was okay since all I wanted to do was see how much changing the “middle” would disrupt the structure.
And so the new plan was:
- Enumerate all the permutations in .
- Enumerate all the permutations in .
- Enumerate all the permutations in .
I admit I never actually ran the enumeration with , because the route with and turned out to be even more promising than I expected. When I compared the empirical data for the sets and , I found that the number of permutations with any particular triple were equal. In other words, the outer blocks were preserved: the bijection does not tamper with the outside blocks of length and .
This meant I was ready to make the following conjecture. Suppose , . There is a bijection
which only involves rearranging the elements of the -th and -st blocks.
4. Rooting out the bijection
At this point I was in a quite good position. I had pinned down the problem to a finding a particular bijection that I was confident had to exist, since it was showing up to the empirical detail.
Let’s call this mythical bijection . How could I figure out what it was?
4.1. Hunch: preserves order-isomorphism
Let me quickly introduce a definition.
Definition 9. We say two words and are order-isomorphic if if and only . Then order-isomorphism gives equivalence classes, and there is a canonical representative where the letters are ; this is called a reduced word.
Example 10. The words , and are order-isomorphic; the last is reduced.
Now I guessed one more property of : this should order-isomorphism.
What do I mean by this? Suppose in one context changed to ; then we would expect that in another situation we should have changing to . Indeed, we expect (empirically) to not touch surrounding outside blocks, and so it would be very strange if behaved differently due to far-away numbers it wasn’t even touching.
So actually I’ll just write for this example, reducing the words in question.
4.2. Keep cheating
With this hunch it’s possible to cheat with C++ again. Here’s how.
Let’s for concreteness suppose and the particular sets Well, it turns out if you look at the data:
- The only element of which starts with and ends with is .
- The only element of which starts with and ends with is .
So that means that is changed to . Thus the empirical data shows that In general, it might not be that clear cut. For example, if we look at the permutations starting with and , there is more than one.
- and are both in .
- and are both in in .
Thus but we can’t tell which one goes to which (although you might be able to guess).
Fortunately, there is lots of data. This example narrowed down to two values, but if you look at other places you might have different data on . Since we think is behaving the same “globally”, we can piece together different pieces of data to get narrower sets. Even better, is a bijection, so once we match either of or , we’ve matched the other.
You know what this sounds like? Perfect matchings.
So here’s the experimental procedure.
- Enumerate all permutations in and .
- Take each possible tuple , and look at the permutations that start and end with those particular four elements. Record the reductions of and for all these permutations. We call these input words and output words, respectively. Each output word is a “candidate” of for a input word.
- For each input word that appeared, take the intersection of all output words that appeared. This gives a bipartite graph , with input words being matched to their candidates.
- Find perfect matchings of the graph.
And with any luck that would tell us what is.
4.3. Results
Luckily, the bipartite graph is quite sparse, and there was only one perfect matching.
246|1357 => 2467|135
247|1356 => 2457|136
256|1347 => 2567|134
257|1346 => 2357|146
267|1345 => 2367|145
346|1257 => 3467|125
347|1256 => 3457|126
356|1247 => 3567|124
357|1246 => 1357|246
367|1245 => 1367|245
456|1237 => 4567|123
457|1236 => 1457|236
467|1235 => 1467|235
567|1234 => 1567|234
If you look at the data, well, there are some clear patterns. Exactly one number is “moving” over from the right half, each time. Also, if is on the right half, then it always moves over.
Anyways, if you stare at this for an hour, you can actually figure out the exact rule:
Claim 11. Given an input , move if is the largest index for which , or if no such index exists.
And indeed, once I have this bijection, it takes maybe only another hour of thinking to verify that this bijection works as advertised, thus solving the original problem.
Rather than writing up what I had found, I celebrated that Sunday evening by playing Wesnoth for 2.5 hours.
5. Generalization
5.1. Surprise
On Monday morning I was mindlessly feeding inputs to the program I had worked on earlier and finally noticed that in fact and also had the same cardinality. Huh.
It seemed too good to be true, but I played around some more, and sure enough, the cardinality of seemed to only depend on the order of the ’s. And so at last I stumbled upon the final form the conjecture, realizing that all along the assumption that I had been working with was a red herring, and that the bijection was really true in much vaster generality. There is a bijection
which only involves rearranging the elements of the -th and -st blocks.
It also meant I had more work to do, and so I was now glad that I hadn’t written up my work from yesterday night.
5.2. More data science
I re-ran the experiment I had done before, now with . (This was interesting, because the elements in question could now have either longest increasing subsequence of length , or instead of length .)
The data I obtained was:
246|13578 => 24678|135
247|13568 => 24578|136
248|13567 => 24568|137
256|13478 => 25678|134
257|13468 => 23578|146
258|13467 => 23568|147
267|13458 => 23678|145
268|13457 => 23468|157
278|13456 => 23478|156
346|12578 => 34678|125
347|12568 => 34578|126
348|12567 => 34568|127
356|12478 => 35678|124
357|12468 => 13578|246
358|12467 => 13568|247
367|12458 => 13678|245
368|12457 => 13468|257
378|12456 => 13478|256
456|12378 => 45678|123
457|12368 => 14578|236
458|12367 => 14568|237
467|12358 => 14678|235
468|12357 => 12468|357
478|12356 => 12478|356
567|12348 => 15678|234
568|12347 => 12568|347
578|12346 => 12578|346
678|12345 => 12678|345
Okay, so it looks like:
- exactly two numbers are moving each time, and
- the length of the longest run is preserved.
Eventually, I was able to work out the details, but they’re more involved than I want to reproduce here. But the idea is that you can move elements “one at a time”: something like
while preserving the length of increasing subsequences at each step.
So, together with the easy observation from the beginning, this not only resolves the original problem, but also gives an elegant generalization. I had now proved:
Theorem 12. For any , …, , the cardinality does not depend on the order of the ’s.
6. Discovered vs invented
Whenever I look back on this, I can’t help thinking just how incredibly lucky I got on this project.
There’s this perpetual debate about whether mathematics is discovered or invented. I think it’s results like this which make the case for “discovered”. I did not really construct the bijection myself: it was “already there” and I found it by examining the data. In another world where did not exist, all the creativity in the world wouldn’t have changed anything.
So anyways, that’s the behind-the-scenes tour of my favorite combinatorics paper.